Python es un lenguiaje muy potente debido a su modularidad y la capacidad de programar al vuelo con una cantidad grande de interpretes (ipython) mi preferido.
Ahora utilizaré algunas ventajas para manejar cadenas de texto.
El objeto Str de Python tiene un montón de métodos para procesamiento de texto. Aquí la lista:
l.__add__ l.decode
l.__class__ l.encode
l.__contains__ l.endswith
l.__delattr__ l.expandtabs
l.__doc__ l.find
l.__eq__ l.format
l.__format__ l.index
l.__ge__ l.isalnum
l.__getattribute__ l.isalpha
l.__getitem__ l.isdigit
l.__getnewargs__ l.islower
l.__getslice__ l.isspace
l.__gt__ l.istitle
l.__hash__ l.isupper
l.__init__ l.join
l.__le__ l.ljust
l.__len__ l.lower
l.__lt__ l.lstrip
l.__mod__ l.partition
l.__mul__ l.replace
l.__ne__ l.rfind
l.__new__ l.rindex
l.__reduce__ l.rjust
l.__reduce_ex__ l.rpartition
l.__repr__ l.rsplit
l.__rmod__ l.rstrip
l.__rmul__ l.split
l.__setattr__ l.splitlines
l.__sizeof__ l.startswith
l.__str__ l.strip
l.__subclasshook__ l.swapcase
l._formatter_field_name_split l.title
l._formatter_parser l.translate
l.capitalize l.upper
l.center l.zfill
l.count
El problema que quiero resolver en este momento es la edición de un nombre de este estilo:
NOMBRE="../../2011/20110809.1549.t1.modis_cal.png"
quiero quedarme con: 20110809.1549.t1.modis_cal.png
o mejor con: 20110809.1549.t.png
He aquí la solución:
Convertimos la cadena NOMBRE a una lista con el método split.
NOMBRE_LISTA=NOMBRE.split("/"); donde "/" es el caracter que servirá para partir la cadena en elementos de la lista (delimitador).
-Ahora NOMBRE_LISTA tiene esta forma:
['..', '..', '2011', '20110809.1549.t1.modis_cal.png']
-De momento sólo nos interesa el campo 3.
-Podemos volver hacer un split a este subcadena utilizando ahora como delimitador el símbolo "."
i.e. NOMBRE_LISTA=NOMBRE_LISTA[3].split(".")
Obs: Estamos sobre escribiendo la lista NOMBRE_LISTA por tanto ahora tendrá esta forma:
['20110809', '1549', 't1', 'modis_cal', 'png']
-Listo! ahora tenemos todo lo que necesitamos. Faltará concatenar (pegar) las cadenas que queramos para formar el nuevo nombre.
NOMBRE=NOMBRE_LISTA[0]+NOMBRE_LISTA[1]+NOMBRE_LISTA[2]+NOMBRE_LISTA[4]
Ya está!
lunes, 7 de noviembre de 2011
viernes, 21 de octubre de 2011
De pesca con grep
Acabo de encontrar una opción chingona para el comando grep.
Muchas veces debemos de buscar varias subcadenas de caracteres dentro de un archivo de texto o una salida de comando (como por ejemplo ls).
Pues hoy me enfrente con ese problema y lo pude resolver de dos maneras.
La respuesta la saque de este sitio: http://www.cyberciti.biz/faq/searching-multiple-words-string-using-grep/
Preámbulo
Debia manipular los archivos que presentaran alguna de las siguientes subcadenas en su nombre: BZ, PM, NU, HO, SL, CR, GT.
Dentro de una carpeta donde hay "chingo" de otros archivos.
Recurrí al buen comando grep con la opción -E seguida de la expresión regular "BZ|CR|GT|HO|NU|PM|SL".
i.e. ls | grep -E "BZ|CR|GT|HO|NU|PM|SL"
La salida de este comando fue únicamente los archivos que me interesaban.
Esto también se puede resolver con el comando fgrep (grep -f) donde toma valores de un archivo de texto simple para cotejarlo con el archivo de texto en cuestión, en este caso la salida de ls.
Por ejemplo, hice un archivo de texto llamado voc.txt con lo siguiente:
BZ
CR
GT
HO
NU
PM
SL
luego utilicé ls | grep -f voc.txt
y me dio el mismo resultado.
FELICIDAD!
Y un saludo pa' la banda linuxera, el grillo, el esdebon, el root, liz y amparo.
Muchas veces debemos de buscar varias subcadenas de caracteres dentro de un archivo de texto o una salida de comando (como por ejemplo ls).
Pues hoy me enfrente con ese problema y lo pude resolver de dos maneras.
La respuesta la saque de este sitio: http://www.cyberciti.biz/faq/searching-multiple-words-string-using-grep/
Preámbulo
Debia manipular los archivos que presentaran alguna de las siguientes subcadenas en su nombre: BZ, PM, NU, HO, SL, CR, GT.
Dentro de una carpeta donde hay "chingo" de otros archivos.
Recurrí al buen comando grep con la opción -E seguida de la expresión regular "BZ|CR|GT|HO|NU|PM|SL".
i.e. ls | grep -E "BZ|CR|GT|HO|NU|PM|SL"
La salida de este comando fue únicamente los archivos que me interesaban.
Esto también se puede resolver con el comando fgrep (grep -f) donde toma valores de un archivo de texto simple para cotejarlo con el archivo de texto en cuestión, en este caso la salida de ls.
Por ejemplo, hice un archivo de texto llamado voc.txt con lo siguiente:
BZ
CR
GT
HO
NU
PM
SL
luego utilicé ls | grep -f voc.txt
y me dio el mismo resultado.
FELICIDAD!
Y un saludo pa' la banda linuxera, el grillo, el esdebon, el root, liz y amparo.
viernes, 17 de junio de 2011
Expresiones regulares en Bash.
Sacado y copiado del Linux Journal
Bash Regular Expressions
May 26, 2008 By Mitch Frazier
When working with regular expressions in a shell script the norm is to use grep or sed or some other external command/program. Since version 3 of bash (released in 2004) there is another option: bash's built-in regular expression comparison operator "=~".
Bash's regular expression comparison operator takes a string on the left and an extended regular expression on the right. It returns 0 (success) if the regular expression matches the string, otherwise it returns 1 (failure).
In addition to doing simple matching, bash regular expressions support sub-patterns surrounded by parenthesis for capturing parts of the match. The matches are assigned to an array variable BASH_REMATCH. The entire match is assigned to BASH_REMATCH[0], the first sub-pattern is assigned to BASH_REMATCH[1], etc..
The following example script takes a regular expression as its first argument and one or more strings to match against. It then cycles through the strings and outputs the results of the match process:
#!/bin.bash
if [[ $# -lt 2 ]]; then
echo "Usage: $0 PATTERN STRINGS..."
exit 1
fi
regex=$1
shift
echo "regex: $regex"
echo
while [[ $1 ]]
do
if [[ $1 =~ $regex ]]; then
echo "$1 matches"
i=1
n=${#BASH_REMATCH[*]}
while [[ $i -lt $n ]]
do
echo " capture[$i]: ${BASH_REMATCH[$i]}"
let i++
done
else
echo "$1 does not match"
fi
shift
done
Assuming the script is saved in "bashre.sh", the following sample shows its output:
# sh bashre.sh 'aa(b{2,3}[xyz])cc' aabbxcc aabbcc
regex: aa(b{2,3}[xyz])cc
aabbxcc matches
capture[1]: bbx
aabbcc does not match
Bash Regular Expressions
May 26, 2008 By Mitch Frazier
When working with regular expressions in a shell script the norm is to use grep or sed or some other external command/program. Since version 3 of bash (released in 2004) there is another option: bash's built-in regular expression comparison operator "=~".
Bash's regular expression comparison operator takes a string on the left and an extended regular expression on the right. It returns 0 (success) if the regular expression matches the string, otherwise it returns 1 (failure).
In addition to doing simple matching, bash regular expressions support sub-patterns surrounded by parenthesis for capturing parts of the match. The matches are assigned to an array variable BASH_REMATCH. The entire match is assigned to BASH_REMATCH[0], the first sub-pattern is assigned to BASH_REMATCH[1], etc..
The following example script takes a regular expression as its first argument and one or more strings to match against. It then cycles through the strings and outputs the results of the match process:
#!/bin.bash
if [[ $# -lt 2 ]]; then
echo "Usage: $0 PATTERN STRINGS..."
exit 1
fi
regex=$1
shift
echo "regex: $regex"
echo
while [[ $1 ]]
do
if [[ $1 =~ $regex ]]; then
echo "$1 matches"
i=1
n=${#BASH_REMATCH[*]}
while [[ $i -lt $n ]]
do
echo " capture[$i]: ${BASH_REMATCH[$i]}"
let i++
done
else
echo "$1 does not match"
fi
shift
done
Assuming the script is saved in "bashre.sh", the following sample shows its output:
# sh bashre.sh 'aa(b{2,3}[xyz])cc' aabbxcc aabbcc
regex: aa(b{2,3}[xyz])cc
aabbxcc matches
capture[1]: bbx
aabbcc does not match
jueves, 16 de junio de 2011
Manual de Cron
Esta es una introducción a cron, cubre lo básico de lo que cron puede hacer y la manera de usarse.
¿Qué es cron?
Cron es el nombre del programa que permite a usuarios Linux/Unix ejecutar automáticamente comandos o scripts (grupos de comandos) a una hora o fecha específica. Es usado normalmente para comandos de tareas administrativas, como respaldos, pero puede ser usado para ejecutar cualquier cosa. Como se define en las páginas del manual de cron (#> man cron) es un demonio que ejecuta programas agendados.
En prácticamente todas las distribuciones de Linux se usa la versión Vixie Cron, por la persona que la desarrolló, que es Paul Vixie, uno de los grandes gurús de Unix, también creador, entre otros sistemas, de BIND que es uno de los servidores DNS más populares del mundo.
Iniciar cron
Cron es un demonio (servicio), lo que significa que solo requiere ser iniciado una vez, generalmente con el mismo arranque del sistema. El servicio de cron se llama crond. En la mayoría de las distribuciones el servicio se instala automáticamente y queda iniciado desde el arranque del sistema, se puede comprobar de varias maneras:
#> /etc/rc.d/init.d/crond status
#> /etc/init.d/crond status Usa cualquiera de los dos dependiendo de tu distro
crond (pid 507) is running...
o si tienes el comando service instalado:
#> service crond status
crond (pid 507) is running...
se puede también revisar a través del comando ps:
# ps -ef | grep crond
si por alguna razón, cron no esta funcionando:
#> /etc/rc.d/init.d/crond start
Starting crond: [ OK ]
Si el servicio no estuviera configurado para arrancar desde un principio, bastaría con agregarlo con el comando chkconfig:
#> chkconfig --level 35 crond on
Con esto lo estarías agregando al nivel de ejecución 3 y 5, para que inicie al momento del arranque del sistema.
Usando cron
Hay al menos dos maneras distintas de usar cron:
La primera es en el directorio etc, donde muy seguramente encontrarás los siguientes directorios:
cron.hourly
cron.daily
cron.weekly
cron.monthly
Si se coloca un archivo tipo script en cualquiera de estos directorios, entonces el script se ejecutará cada hora, cada día, cada semana o cada mes, dependiendo del directorio.
Para que el archivo pueda ser ejecutado tiene que ser algo similar a lo siguiente:
#!/bin/sh
#script que genera un respaldo
cd /usr/documentos
tar czf * respaldo
cp respaldo /otra_directorio/.
Nótese que la primera línea empieza con #!, que indica que se trata de un script shell de bash, las demás líneas son los comandos que deseamos ejecute el script. Este script podría nombrarse por ejemplo respaldo.sh y también debemos cambiarle los permisos correspondientes para que pueda ser ejecutado, por ejemplo:
#> chmod 700 respaldo.sh
#> ls -l respaldo.sh
-rwx------ 1 root root 0 Jul 20 09:30 respaldo.sh
La "x" en el grupo de permisos del propietario (rwx) indica que puede ser ejecutado.
Si este script lo dejamos en cron.hourly, entonces se ejecutará cada hora con un minuto de todos los días, en un momento se entenderá el porque.
Como segundo modo de ejecutar o usar cron es a través de manipular directamente el archivo /etc/crontab. En la instalación por defecto de varias distribuciones Linux, este archivo se verá a algo como lo siguiente:
#> cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/
# run-parts
01 * * * * root run-parts /etc/cron.hourly
02 4 * * * root run-parts /etc/cron.daily
22 4 * * 0 root run-parts /etc/cron.weekly
42 4 1 * * root run-parts /etc/cron.monthly
Las primeras cuatro líneas son variables que indican lo siguiente:
SHELL es el 'shell' bajo el cual se ejecuta el cron. Si no se especifica, se tomará por defecto el indicado en la línea /etc/passwd correspondiente al usuario que este ejecutando cron.
PATH contiene o indica la ruta a los directorios en los cuales cron buscará el comando a ejecutar. Este path es distinto al path global del sistema o del usuario.
MAIL TO es a quien se le envía la salida del comando (si es que este tiene alguna salida). Cron enviará un correo a quien se especifique en este variable, es decir, debe ser un usuario válido del sistema o de algún otro sistema. Si no se especifica, entonces cron enviará el correo al usuario propietario del comando que se ejecuta.
HOME es el directorio raíz o principal del comando cron, si no se indica entonces, la raíz será la que se indique en el archivo /etc/passwd correspondiente al usuario que ejecuta cron.
Los comentarios se indican con # al inicio de la línea.
Después de lo anterior vienen las líneas que ejecutan las tareas programadas propiamente. No hay límites de cuantas tareas pueda haber, una por renglón. Los campos (son 7) que forman estas líneas están formados de la siguiente manera:
Minuto Hora DiaDelMes Mes DiaDeLaSemana Usuario Comando
Campo Descripción
Minuto Controla el minuto de la hora en que el comando será ejecutado, este valor debe de estar entre 0 y 59.
Hora Controla la hora en que el comando será ejecutado, se especifica en un formato de 24 horas, los valores deben estar entre 0 y 23, 0 es medianoche.
Día del Mes Día del mes en que se quiere ejecutar el comando. Por ejemplo se indicaría 20, para ejecutar el comando el día 20 del mes.
Mes Mes en que el comando se ejecutará, puede ser indicado numéricamente (1-12), o por el nombre del mes en inglés, solo las tres primeras letras.
Día de la semana Día en la semana en que se ejecutará el comando, puede ser numérico (0-7) o por el nombre del día en inglés, solo las tres primeras letras. (0 y 7 = domingo)
Usuario Usuario que ejecuta el comando.
Comando Comando, script o programa que se desea ejecutar. Este campo puede contener múltiples palabras y espacios.
Un asterisco * como valor en los primeros cinco campos, indicará inicio-fin del campo, es decir todo. Un * en el campo de minuto indicará todos los minutos.
Para entender bien esto de los primeros 5 campos y el asterisco usaré mejor varios ejemplos:
Ejemplo Descripción
01 * * * * Se ejecuta al minuto 1 de cada hora de todos los días
15 8 * * * A las 8:15 a.m. de cada día
15 20 * * * A las 8:15 p.m. de cada día
00 5 * * 0 A las 5 a.m. todos los domingos
* 5 * * Sun Cada minuto de 5:00a.m. a 5:59a.m. todos los domingos
45 19 1 * * A las 7:45 p.m. del primero de cada mes
01 * 20 7 * Al minuto 1 de cada hora del 20 de julio
10 1 * 12 1 A la 1:10 a.m. todos los lunes de diciembre
00 12 16 * Wen Al mediodía de los días 16 de cada mes y que sea Miércoles
30 9 20 7 4 A las 9:30 a.m. del dia 20 de julio y que sea jueves
30 9 20 7 * A las 9:30 a.m. del dia 20 de julio sin importar el día de la semana
20 * * * 6 Al minuto 20 de cada hora de los sábados
20 * * 1 6 Al minuto 20 de cada hora de los sábados de enero
También es posible especificar listas en los campos. Las listas pueden estar en la forma de 1,2,3,4 o en la forma de 1-4 que sería lo mismo. Cron, de igual manera soporta incrementos en las listas, que se indican de la siguiente manera:
Valor o lista/incremento
De nuevo, es más fácil entender las listas e incrementos con ejemplos:
Ejemplo Descripción
59 11 * 1-3 1,2,3,4,5 A las 11:59 a.m. de lunes a viernes, de enero a marzo
45 * 10-25 * 6-7 Al minuto 45 de todas las horas de los días 10 al 25 de todos los meses y que el día sea sábado o domingo
10,30,50 * * * 1,3,5 En el minuto 10, 30 y 50 de todas las horas de los días lunes, miércoles y viernes
*/15 10-14 * * * Cada quince minutos de las 10:00a.m. a las 2:00p.m.
* 12 1-10/2 2,8 * Todos los minutos de las 12 del día, en los días 1,3,5,7 y 9 de febrero y agosto. (El incremento en el tercer campo es de 2 y comienza a partir del 1)
0 */5 1-10,15,20-23 * 3 Cada 5 horas de los días 1 al 10, el día 15 y del día 20 al 23 de cada mes y que el día sea miércoles
3/3 2/4 2 2 2 Cada 3 minutos empezando por el minuto 3 (3,6,9, etc.) de las horas 2,6,10, etc (cada 4 horas empezando en la hora 2) del día 2 de febrero y que sea martes
Como se puede apreciar en el último ejemplo la tarea cron que estuviera asignada a ese renglón con esos datos, solo se ejecutaría si se cumple con los 5 campos (AND). Es decir, para que la tarea se ejecute tiene que ser un martes 2 de febrero a las 02:03. Siempre es un AND booleano que solo resulta verdadero si los 5 campos son ciertos en el minuto específico.
El caso anterior deja claro entonces que:
El programa cron se invoca cada minuto y ejecuta las tareas que sus campos se cumplan en ese preciso minuto.
Incluyendo el campo del usuario y el comando, los renglones de crontab podrían quedar entonces de la siguiente manera:
0 22 * * * root /usr/respaldodiario.sh
0 23 * * 5 root /usr/respaldosemanal.sh
0 8,20 * * * sergio mail -s "sistema funcionando" sgd@ejemplo.com
Las dos primeras líneas las ejecuta el usuario root y la primera ejecuta a las 10 de la noche de todos los días el script que genera un respaldo diario. La seguna ejecuta a las 11 de la noche de todos los viernes un script que genera un respaldo semana. La tercera línea la ejecuta el usuario sergio y se ejecutaría a las 8 de la mañana y 8 de la noche de todos los día y el comando es enviar un correo a la cuenta sgd@ejemplo.com con el asunto "sistema funcionando", una manera de que un administrador este enterado de que un sistema remoto esta activo en las horas indicadas, sino recibe un correo en esas horas, algo anda mal.
Siendo root, es posible entonces, modificar directamente crontab:
#> vi /etc/crontab
Ejecutando Cron con múltiples usuarios, comando crontab
Linux es un sistema multiusuario y cron es de las aplicaciones que soporta el trabajo con varios usuarios a la vez. Cada usuario puede tener su propio archivo crontab, de hecho el /etc/crontab se asume que es el archivo crontab del usuario root, aunque no hay problema que se incluyan otros usuarios, y de ahí el sexto campo que indica precisamente quien es el usuario que ejecuta la tarea y es obligatorio en /etc/crontab.
Pero cuando los usuarios normales (e incluso root) desean generar su propio archivo de crontab, entonces utilizaremos el comando crontab.
En el directorio /var/spool/cron (puede variar según la distribución), se genera un archivo cron para cada usuario, este archivo aunque es de texto, no debe editarse directamente.
Se tiene entonces, dos situaciones, generar directamente el archivo crontab con el comando:
$> crontab -e
Con lo cual se abrira el editor por default (generalemente vi) con el archivo llamado crontab vacio y donde el usuario ingresará su tabla de tareas y que se guardará automáticamente como /var/spool/cron/usuario.
El otro caso es que el usuario edite un archivo de texto normal con las entradas de las tareas y como ejemplo lo nombre 'mi_cron', después el comando $> crontab mi_cron se encargará de establecerlo como su archivo cron del usuario en /var/spool/cron/usuario:
$> vi mi_cron
# borra archivos de carpeta compartida
0 20 * * * rm -f /home/sergio/compartidos/*
# ejecuta un script que realiza un respaldo de la carpeta documentos el primer día de cada mes
0 22 1 * * /home/sergio/respaldomensual.sh
# cada 5 horas de lun a vie, se asegura que los permisos sean los correctos en mi home
1 *5 * * * 1-5 chmod -R 640 /home/sergio/*
:wq (se guarda el archivo)
$> ls
mi_cron
$> crontab mi_cron
(se establece en /var/spool/cron/usuario)
Resumiendo lo anterior y considerando otras opciones de crontab:
$> crontab archivo.cron (establecerá el archivo.cron como el crontab del usuario)
$> crontab -e (abrirá el editor preestablecido donde se podrá crear o editar el archivo crontab)
$> crontab -l (lista el crontab actual del usuario, sus tareas de cron)
$> crontab -r (elimina el crontab actual del usuario)
En algunas distribuciones cuando se editan crontabs de usuarios normales es necesario reiniciar el servicio para que se puedan releer los archivos de crontab en /var/spool/cron.
#> service crond restart
Para entender mejor como iniciar/detener/reiniciar servicios, en este artículo encontrarás más información.
Controlando el acceso a cron
Cron permite controlar que usuarios pueden o no pueden usar los servicios de cron. Esto se logra de una manera muy sencilla a través de los siguientes archivos:
/etc/cron.allow
/etc/cron.deny
Para impedir que un usuario utilice cron o mejor dicho el comando crontab, basta con agregar su nombre de usuario al archivo /etc/cron.deny, para permitirle su uso entonces sería agregar su nombre de usuario en /etc/cron.allow, si por alguna razón se desea negar el uso de cron a todos los usuarios, entonces se puede escribir la palabra ALL al inicio de cron.deny y con eso bastaría.
#> echo ALL >>/etc/cron.deny
o para agregar un usuario mas a cron.allow
#> echo juan >>/etc/cron.allow
Si no existe el archivo cron.allow ni el archivo cron.deny, en teoría el uso de cron esta entonces sin restricciones de usuario. Si se añaden nombres de usuarios en cron.allow, sin crear un archivo cron.deny, tendrá el mismo efecto que haberlo creado con la palabra ALL. Esto quiere decir que una vez creado cron.allow con un solo usuario, siempre se tendrán que especificar los demás usuarios que se quiere usen cron, en este archivo.
Tomado de: http://www.linuxtotal.com.mx/index.php?cont=info_admon_006
Copyright 2005-2011 Sergio González Durán
Se concede permiso para copiar, distribuir y/o modificar este documento siempre y cuando se cite al autor y la fuente de linuxtotal.com.mx y según los términos de la GNU Free Documentation License, Versión 1.2 o cualquiera posterior publicada por la Free Software Foundation.
autor: sergio.gonzalez.duran@gmail.com
¿Qué es cron?
Cron es el nombre del programa que permite a usuarios Linux/Unix ejecutar automáticamente comandos o scripts (grupos de comandos) a una hora o fecha específica. Es usado normalmente para comandos de tareas administrativas, como respaldos, pero puede ser usado para ejecutar cualquier cosa. Como se define en las páginas del manual de cron (#> man cron) es un demonio que ejecuta programas agendados.
En prácticamente todas las distribuciones de Linux se usa la versión Vixie Cron, por la persona que la desarrolló, que es Paul Vixie, uno de los grandes gurús de Unix, también creador, entre otros sistemas, de BIND que es uno de los servidores DNS más populares del mundo.
Iniciar cron
Cron es un demonio (servicio), lo que significa que solo requiere ser iniciado una vez, generalmente con el mismo arranque del sistema. El servicio de cron se llama crond. En la mayoría de las distribuciones el servicio se instala automáticamente y queda iniciado desde el arranque del sistema, se puede comprobar de varias maneras:
#> /etc/rc.d/init.d/crond status
#> /etc/init.d/crond status Usa cualquiera de los dos dependiendo de tu distro
crond (pid 507) is running...
o si tienes el comando service instalado:
#> service crond status
crond (pid 507) is running...
se puede también revisar a través del comando ps:
# ps -ef | grep crond
si por alguna razón, cron no esta funcionando:
#> /etc/rc.d/init.d/crond start
Starting crond: [ OK ]
Si el servicio no estuviera configurado para arrancar desde un principio, bastaría con agregarlo con el comando chkconfig:
#> chkconfig --level 35 crond on
Con esto lo estarías agregando al nivel de ejecución 3 y 5, para que inicie al momento del arranque del sistema.
Usando cron
Hay al menos dos maneras distintas de usar cron:
La primera es en el directorio etc, donde muy seguramente encontrarás los siguientes directorios:
cron.hourly
cron.daily
cron.weekly
cron.monthly
Si se coloca un archivo tipo script en cualquiera de estos directorios, entonces el script se ejecutará cada hora, cada día, cada semana o cada mes, dependiendo del directorio.
Para que el archivo pueda ser ejecutado tiene que ser algo similar a lo siguiente:
#!/bin/sh
#script que genera un respaldo
cd /usr/documentos
tar czf * respaldo
cp respaldo /otra_directorio/.
Nótese que la primera línea empieza con #!, que indica que se trata de un script shell de bash, las demás líneas son los comandos que deseamos ejecute el script. Este script podría nombrarse por ejemplo respaldo.sh y también debemos cambiarle los permisos correspondientes para que pueda ser ejecutado, por ejemplo:
#> chmod 700 respaldo.sh
#> ls -l respaldo.sh
-rwx------ 1 root root 0 Jul 20 09:30 respaldo.sh
La "x" en el grupo de permisos del propietario (rwx) indica que puede ser ejecutado.
Si este script lo dejamos en cron.hourly, entonces se ejecutará cada hora con un minuto de todos los días, en un momento se entenderá el porque.
Como segundo modo de ejecutar o usar cron es a través de manipular directamente el archivo /etc/crontab. En la instalación por defecto de varias distribuciones Linux, este archivo se verá a algo como lo siguiente:
#> cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/
# run-parts
01 * * * * root run-parts /etc/cron.hourly
02 4 * * * root run-parts /etc/cron.daily
22 4 * * 0 root run-parts /etc/cron.weekly
42 4 1 * * root run-parts /etc/cron.monthly
Las primeras cuatro líneas son variables que indican lo siguiente:
SHELL es el 'shell' bajo el cual se ejecuta el cron. Si no se especifica, se tomará por defecto el indicado en la línea /etc/passwd correspondiente al usuario que este ejecutando cron.
PATH contiene o indica la ruta a los directorios en los cuales cron buscará el comando a ejecutar. Este path es distinto al path global del sistema o del usuario.
MAIL TO es a quien se le envía la salida del comando (si es que este tiene alguna salida). Cron enviará un correo a quien se especifique en este variable, es decir, debe ser un usuario válido del sistema o de algún otro sistema. Si no se especifica, entonces cron enviará el correo al usuario propietario del comando que se ejecuta.
HOME es el directorio raíz o principal del comando cron, si no se indica entonces, la raíz será la que se indique en el archivo /etc/passwd correspondiente al usuario que ejecuta cron.
Los comentarios se indican con # al inicio de la línea.
Después de lo anterior vienen las líneas que ejecutan las tareas programadas propiamente. No hay límites de cuantas tareas pueda haber, una por renglón. Los campos (son 7) que forman estas líneas están formados de la siguiente manera:
Minuto Hora DiaDelMes Mes DiaDeLaSemana Usuario Comando
Campo Descripción
Minuto Controla el minuto de la hora en que el comando será ejecutado, este valor debe de estar entre 0 y 59.
Hora Controla la hora en que el comando será ejecutado, se especifica en un formato de 24 horas, los valores deben estar entre 0 y 23, 0 es medianoche.
Día del Mes Día del mes en que se quiere ejecutar el comando. Por ejemplo se indicaría 20, para ejecutar el comando el día 20 del mes.
Mes Mes en que el comando se ejecutará, puede ser indicado numéricamente (1-12), o por el nombre del mes en inglés, solo las tres primeras letras.
Día de la semana Día en la semana en que se ejecutará el comando, puede ser numérico (0-7) o por el nombre del día en inglés, solo las tres primeras letras. (0 y 7 = domingo)
Usuario Usuario que ejecuta el comando.
Comando Comando, script o programa que se desea ejecutar. Este campo puede contener múltiples palabras y espacios.
Un asterisco * como valor en los primeros cinco campos, indicará inicio-fin del campo, es decir todo. Un * en el campo de minuto indicará todos los minutos.
Para entender bien esto de los primeros 5 campos y el asterisco usaré mejor varios ejemplos:
Ejemplo Descripción
01 * * * * Se ejecuta al minuto 1 de cada hora de todos los días
15 8 * * * A las 8:15 a.m. de cada día
15 20 * * * A las 8:15 p.m. de cada día
00 5 * * 0 A las 5 a.m. todos los domingos
* 5 * * Sun Cada minuto de 5:00a.m. a 5:59a.m. todos los domingos
45 19 1 * * A las 7:45 p.m. del primero de cada mes
01 * 20 7 * Al minuto 1 de cada hora del 20 de julio
10 1 * 12 1 A la 1:10 a.m. todos los lunes de diciembre
00 12 16 * Wen Al mediodía de los días 16 de cada mes y que sea Miércoles
30 9 20 7 4 A las 9:30 a.m. del dia 20 de julio y que sea jueves
30 9 20 7 * A las 9:30 a.m. del dia 20 de julio sin importar el día de la semana
20 * * * 6 Al minuto 20 de cada hora de los sábados
20 * * 1 6 Al minuto 20 de cada hora de los sábados de enero
También es posible especificar listas en los campos. Las listas pueden estar en la forma de 1,2,3,4 o en la forma de 1-4 que sería lo mismo. Cron, de igual manera soporta incrementos en las listas, que se indican de la siguiente manera:
Valor o lista/incremento
De nuevo, es más fácil entender las listas e incrementos con ejemplos:
Ejemplo Descripción
59 11 * 1-3 1,2,3,4,5 A las 11:59 a.m. de lunes a viernes, de enero a marzo
45 * 10-25 * 6-7 Al minuto 45 de todas las horas de los días 10 al 25 de todos los meses y que el día sea sábado o domingo
10,30,50 * * * 1,3,5 En el minuto 10, 30 y 50 de todas las horas de los días lunes, miércoles y viernes
*/15 10-14 * * * Cada quince minutos de las 10:00a.m. a las 2:00p.m.
* 12 1-10/2 2,8 * Todos los minutos de las 12 del día, en los días 1,3,5,7 y 9 de febrero y agosto. (El incremento en el tercer campo es de 2 y comienza a partir del 1)
0 */5 1-10,15,20-23 * 3 Cada 5 horas de los días 1 al 10, el día 15 y del día 20 al 23 de cada mes y que el día sea miércoles
3/3 2/4 2 2 2 Cada 3 minutos empezando por el minuto 3 (3,6,9, etc.) de las horas 2,6,10, etc (cada 4 horas empezando en la hora 2) del día 2 de febrero y que sea martes
Como se puede apreciar en el último ejemplo la tarea cron que estuviera asignada a ese renglón con esos datos, solo se ejecutaría si se cumple con los 5 campos (AND). Es decir, para que la tarea se ejecute tiene que ser un martes 2 de febrero a las 02:03. Siempre es un AND booleano que solo resulta verdadero si los 5 campos son ciertos en el minuto específico.
El caso anterior deja claro entonces que:
El programa cron se invoca cada minuto y ejecuta las tareas que sus campos se cumplan en ese preciso minuto.
Incluyendo el campo del usuario y el comando, los renglones de crontab podrían quedar entonces de la siguiente manera:
0 22 * * * root /usr/respaldodiario.sh
0 23 * * 5 root /usr/respaldosemanal.sh
0 8,20 * * * sergio mail -s "sistema funcionando" sgd@ejemplo.com
Las dos primeras líneas las ejecuta el usuario root y la primera ejecuta a las 10 de la noche de todos los días el script que genera un respaldo diario. La seguna ejecuta a las 11 de la noche de todos los viernes un script que genera un respaldo semana. La tercera línea la ejecuta el usuario sergio y se ejecutaría a las 8 de la mañana y 8 de la noche de todos los día y el comando es enviar un correo a la cuenta sgd@ejemplo.com con el asunto "sistema funcionando", una manera de que un administrador este enterado de que un sistema remoto esta activo en las horas indicadas, sino recibe un correo en esas horas, algo anda mal.
Siendo root, es posible entonces, modificar directamente crontab:
#> vi /etc/crontab
Ejecutando Cron con múltiples usuarios, comando crontab
Linux es un sistema multiusuario y cron es de las aplicaciones que soporta el trabajo con varios usuarios a la vez. Cada usuario puede tener su propio archivo crontab, de hecho el /etc/crontab se asume que es el archivo crontab del usuario root, aunque no hay problema que se incluyan otros usuarios, y de ahí el sexto campo que indica precisamente quien es el usuario que ejecuta la tarea y es obligatorio en /etc/crontab.
Pero cuando los usuarios normales (e incluso root) desean generar su propio archivo de crontab, entonces utilizaremos el comando crontab.
En el directorio /var/spool/cron (puede variar según la distribución), se genera un archivo cron para cada usuario, este archivo aunque es de texto, no debe editarse directamente.
Se tiene entonces, dos situaciones, generar directamente el archivo crontab con el comando:
$> crontab -e
Con lo cual se abrira el editor por default (generalemente vi) con el archivo llamado crontab vacio y donde el usuario ingresará su tabla de tareas y que se guardará automáticamente como /var/spool/cron/usuario.
El otro caso es que el usuario edite un archivo de texto normal con las entradas de las tareas y como ejemplo lo nombre 'mi_cron', después el comando $> crontab mi_cron se encargará de establecerlo como su archivo cron del usuario en /var/spool/cron/usuario:
$> vi mi_cron
# borra archivos de carpeta compartida
0 20 * * * rm -f /home/sergio/compartidos/*
# ejecuta un script que realiza un respaldo de la carpeta documentos el primer día de cada mes
0 22 1 * * /home/sergio/respaldomensual.sh
# cada 5 horas de lun a vie, se asegura que los permisos sean los correctos en mi home
1 *5 * * * 1-5 chmod -R 640 /home/sergio/*
:wq (se guarda el archivo)
$> ls
mi_cron
$> crontab mi_cron
(se establece en /var/spool/cron/usuario)
Resumiendo lo anterior y considerando otras opciones de crontab:
$> crontab archivo.cron (establecerá el archivo.cron como el crontab del usuario)
$> crontab -e (abrirá el editor preestablecido donde se podrá crear o editar el archivo crontab)
$> crontab -l (lista el crontab actual del usuario, sus tareas de cron)
$> crontab -r (elimina el crontab actual del usuario)
En algunas distribuciones cuando se editan crontabs de usuarios normales es necesario reiniciar el servicio para que se puedan releer los archivos de crontab en /var/spool/cron.
#> service crond restart
Para entender mejor como iniciar/detener/reiniciar servicios, en este artículo encontrarás más información.
Controlando el acceso a cron
Cron permite controlar que usuarios pueden o no pueden usar los servicios de cron. Esto se logra de una manera muy sencilla a través de los siguientes archivos:
/etc/cron.allow
/etc/cron.deny
Para impedir que un usuario utilice cron o mejor dicho el comando crontab, basta con agregar su nombre de usuario al archivo /etc/cron.deny, para permitirle su uso entonces sería agregar su nombre de usuario en /etc/cron.allow, si por alguna razón se desea negar el uso de cron a todos los usuarios, entonces se puede escribir la palabra ALL al inicio de cron.deny y con eso bastaría.
#> echo ALL >>/etc/cron.deny
o para agregar un usuario mas a cron.allow
#> echo juan >>/etc/cron.allow
Si no existe el archivo cron.allow ni el archivo cron.deny, en teoría el uso de cron esta entonces sin restricciones de usuario. Si se añaden nombres de usuarios en cron.allow, sin crear un archivo cron.deny, tendrá el mismo efecto que haberlo creado con la palabra ALL. Esto quiere decir que una vez creado cron.allow con un solo usuario, siempre se tendrán que especificar los demás usuarios que se quiere usen cron, en este archivo.
Tomado de: http://www.linuxtotal.com.mx/index.php?cont=info_admon_006
Copyright 2005-2011 Sergio González Durán
Se concede permiso para copiar, distribuir y/o modificar este documento siempre y cuando se cite al autor y la fuente de linuxtotal.com.mx y según los términos de la GNU Free Documentation License, Versión 1.2 o cualquiera posterior publicada por la Free Software Foundation.
autor: sergio.gonzalez.duran@gmail.com
Execelente manual para integrar servicios web.
Me encontré este manual para integrar en una red local, en diferentes computadoras seervicios de autenticación LDAP, servidor DNS, DHCP, FTP, SAMBA, NFS, etc. En fin la última práctica del curso de administración está aquí. Este es el enlance super manual
Llamadas a procedimientos remotos (RPC)
Algunas veces no puede interesar ejecutar programas o procesos de forma remota en un servidor. Para poder hacer esto existe RPC.
Funcionamiento:
Una llamada RPC es inicializada por el cliente, quien manda una petición a un servidor remoto para que ejecute el procedimiento especificado con sus respectivos parámetros. El servidor remoto manda una respuesta al cliente y la aplicación continua su ejecución. Mientras el servidor ejecuta el procedimiento el cliente se bloquea hasta que el servidor termina y le avisa.
Hay muchas variaciones y sutiliesas en las distintas implementaciones de RPC, lo que hace que haya incompatibilidades entre ellos.
Una diferencia importante entre llamadas remotas y llamadas locales es que las primeras pueden fallar por problemas de conexión en la red. Estas llamadas deben lidiar con estas fallas sin saber a si realmente el procedimiento fue invocado. Es por esto que el código de estos procedimientos debe estar escrito en un lenguaje de bajo nivel.
El comando rpcinfo
Este programa da información de los programas RPC que tiene habilitado un servidor.
$rpcinfo -p
da información de la máquina local
$rpcinfo -p host
Da información del servidor host
Muestra información de todas las máquinas en la red local que están corriendo el servicio de Yellow Pages:
$rpcinfo -b ypserv 'version' | uniq
Donde 'version' es la versión actual de Yellow Pages obtenida de los resultados anteriores.
Funcionamiento:
Una llamada RPC es inicializada por el cliente, quien manda una petición a un servidor remoto para que ejecute el procedimiento especificado con sus respectivos parámetros. El servidor remoto manda una respuesta al cliente y la aplicación continua su ejecución. Mientras el servidor ejecuta el procedimiento el cliente se bloquea hasta que el servidor termina y le avisa.
Hay muchas variaciones y sutiliesas en las distintas implementaciones de RPC, lo que hace que haya incompatibilidades entre ellos.
Una diferencia importante entre llamadas remotas y llamadas locales es que las primeras pueden fallar por problemas de conexión en la red. Estas llamadas deben lidiar con estas fallas sin saber a si realmente el procedimiento fue invocado. Es por esto que el código de estos procedimientos debe estar escrito en un lenguaje de bajo nivel.
El comando rpcinfo
Este programa da información de los programas RPC que tiene habilitado un servidor.
$rpcinfo -p
da información de la máquina local
$rpcinfo -p host
Da información del servidor host
Muestra información de todas las máquinas en la red local que están corriendo el servicio de Yellow Pages:
$rpcinfo -b ypserv 'version' | uniq
Donde 'version' es la versión actual de Yellow Pages obtenida de los resultados anteriores.
lunes, 13 de junio de 2011
Configurar un servidor samba y compartir impresoras Linux-Windows
Esta vez vamos a compartir archivos e impresoras entre sistemas operativos tipo Linux y Güindows. Para esto sera necesario compartirlos por medio del sistema de archivos Samba.
http://www.samba.org/
Lo primero que tenemos que hacer es instalar los paquetes:
samba
samba-common
samba-client
Una vez instalados deberemos editar el archivo de configuración ubicado en /etc/samba/smb.conf
Para determinar que carpetas van a ser las que vamos a compartir. Por ejemplo, supongamos que queremos compartir toda la carpeta home del usuario juan.
Entonces deberemos proceder de la siguiente manera:
_____________________________________________________
[public]
comment = Public Folder
path = /home/juan
public = yes
writable = yes
create mask = 0777
directory mask = 0777
force user = nobody
force group = nogroup
guest ok = yes
_______________________________________________________
Si queremos compartir archivos sin restricciones de usuarios lo podemos hacer así.
Dentro de este archivo vamos a buscar la linea que diga lo siguiente:
; security = user
Y la sustituimos por
security = SHARE
Reiniciamos el servidor samba con:
/etc/init.d/samba restart
Para poder tener acceso desde windows, debemos dar click en el programa "ejecutar" o "run" e introducir la dirección ip donde está Samba. En mi caso esta en: 192.168.1.64
Listo!
_____________________________________________________
Impresión
Modificar archivo de configuración de Cups para que soporte el protocolo de SAMBA.
Modificar el archivo de configuración de SAMBA para que soporte impresión.
Seguir la instrucciones en Windows para agregar impresora.
_____________________________________________________
Máquina vitual.
Si tienes windows en una máquina virtual y quieres compartir archivos e impresoras con otras máquinas dentro de la red local deberás configurar un puente. Qemo lo hace automático pero Virtualbox no.
Revisa http://www.dedoimedo.com/computers/virtualbox-network-sharing.html para más información.
http://www.samba.org/
Lo primero que tenemos que hacer es instalar los paquetes:
samba
samba-common
samba-client
Una vez instalados deberemos editar el archivo de configuración ubicado en /etc/samba/smb.conf
Para determinar que carpetas van a ser las que vamos a compartir. Por ejemplo, supongamos que queremos compartir toda la carpeta home del usuario juan.
Entonces deberemos proceder de la siguiente manera:
_____________________________________________________
[public]
comment = Public Folder
path = /home/juan
public = yes
writable = yes
create mask = 0777
directory mask = 0777
force user = nobody
force group = nogroup
guest ok = yes
_______________________________________________________
Si queremos compartir archivos sin restricciones de usuarios lo podemos hacer así.
Dentro de este archivo vamos a buscar la linea que diga lo siguiente:
; security = user
Y la sustituimos por
security = SHARE
Reiniciamos el servidor samba con:
/etc/init.d/samba restart
Para poder tener acceso desde windows, debemos dar click en el programa "ejecutar" o "run" e introducir la dirección ip donde está Samba. En mi caso esta en: 192.168.1.64
Listo!
_____________________________________________________
Impresión
Modificar archivo de configuración de Cups para que soporte el protocolo de SAMBA.
Modificar el archivo de configuración de SAMBA para que soporte impresión.
Seguir la instrucciones en Windows para agregar impresora.
_____________________________________________________
Máquina vitual.
Si tienes windows en una máquina virtual y quieres compartir archivos e impresoras con otras máquinas dentro de la red local deberás configurar un puente. Qemo lo hace automático pero Virtualbox no.
Revisa http://www.dedoimedo.com/computers/virtualbox-network-sharing.html para más información.
domingo, 12 de junio de 2011
Monitoreo de visitas con Apache
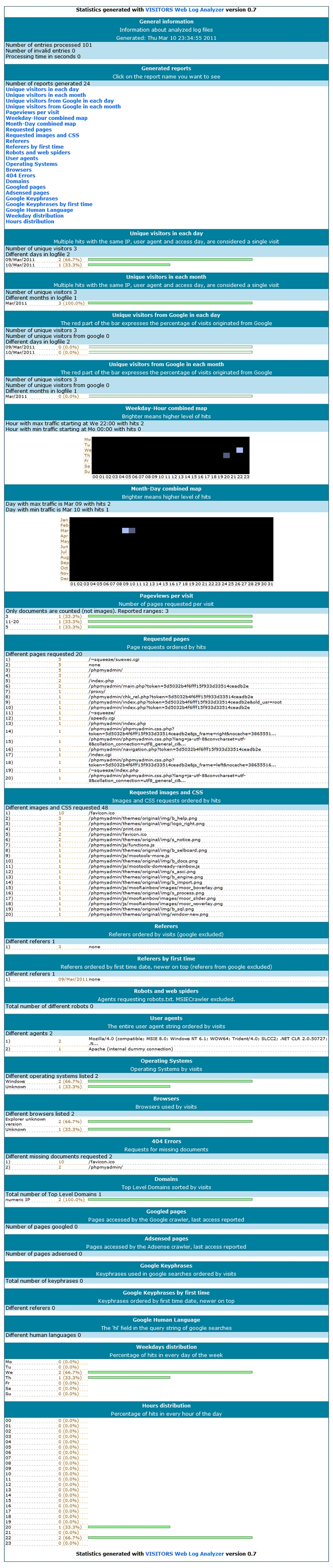
Esta vez vamos a utilizar un programa para analizar de forma fácil y rápida los logs de Apache para ver cuantos usuarios se han conectado a nuestro servidor Web. utilizaremos la interfaz web que provee el mismo programa. Esta aplicación se llama visitors y esta en los repositorios de Debian y Ubuntu.
Más información en:http://packages.debian.org/unstable/web/visitors
Instalémoslo
$ aptitude -y install visitors graphviz
$ mkdir /var/www/visitors
Editemos el archivo /etc/apache2/sites-available/default
añadiendo lo siguiente:
# Para configuración de visitors
Order Deny,Allow
Deny from all
Allow from localhost
Allow from 192.168.1.0/24 #Para permitir acceso al log en todo el segmento 1 de mi red local.
# IP address you allow
Cámbialo por las direcciones que necesites.
Reiniciemos apache: /etc/init.d/apache2 restart
Usos!
Generemos el reporte:
$ visitors -A /var/log/apache2/access.log -o html > /var/www/visitors/index.html
Generar reporte de páginas visitadas
$ visitors -A -m 30 /var/log/apache2/access.log -o html --trails --prefix http://TUSERVIDOR > /var/www/visitors/trails.html
Generar gráfica de páginas visitadas
$ visitors /var/log/apache2/access.log --prefix http://TUSERVIDOR -V > /var/www/visitors/graph.dot
Utiliza el programa graphviz
$ dot -Tpng /var/www/visitors/graph.dot > /var/www/visitors/graph.png
¿Qué routers visitamos antes de conectarnos con un servidor?
La internet es una red hipercompleja por donde pasa todo tipo de información. Para conectarnos a un servidor particular (e.g www.duckduckgo.com) nuestros paquetes viajan por varias máquinas que van encaminando estos paquetes por la red hasta llegar al destino requerido. Para saber por donde va pasando esta información, se puede utilizar el comando traceroute.
Este comando esta en los repositorios de Debian y Ubuntu. Para más información visita: http://traceroute.sourceforge.net/
Una vez instalado su utilización es muy fácil.
Aquí les muestro la salida del comando haciendo una consulta para el servidor www.gmail.com
traceroute to www.gmail.com (74.125.224.214), 30 hops max, 60 byte packets
1 home (192.168.1.254) 4.878 ms 5.503 ms 5.775 ms
2 dsl-servicio-l200.uninet.net.mx (200.38.193.226) 19.806 ms 22.386 ms 27.846 ms
3 reg-mex-roma-13-ge2-0-0.uninet.net.mx (201.125.67.188) 29.120 ms 31.808 ms 32.177 ms
4 bb-la-onewilshire-10-pos0-4-2-0.uninet.net.mx (201.154.119.230) 68.827 ms 72.369 ms 72.704 ms
5 * * *
6 * 64.233.174.41 (64.233.174.41) 63.324 ms 51.401 ms
7 72.14.236.13 (72.14.236.13) 53.271 ms 55.641 ms 57.164 ms
8 74.125.224.214 (74.125.224.214) 59.162 ms 62.871 ms 63.266 ms
Con este comando nos podemos dar cuenta de posibles ataques de de suplantación de identidad.
Este comando esta en los repositorios de Debian y Ubuntu. Para más información visita: http://traceroute.sourceforge.net/
Una vez instalado su utilización es muy fácil.
Aquí les muestro la salida del comando haciendo una consulta para el servidor www.gmail.com
traceroute to www.gmail.com (74.125.224.214), 30 hops max, 60 byte packets
1 home (192.168.1.254) 4.878 ms 5.503 ms 5.775 ms
2 dsl-servicio-l200.uninet.net.mx (200.38.193.226) 19.806 ms 22.386 ms 27.846 ms
3 reg-mex-roma-13-ge2-0-0.uninet.net.mx (201.125.67.188) 29.120 ms 31.808 ms 32.177 ms
4 bb-la-onewilshire-10-pos0-4-2-0.uninet.net.mx (201.154.119.230) 68.827 ms 72.369 ms 72.704 ms
5 * * *
6 * 64.233.174.41 (64.233.174.41) 63.324 ms 51.401 ms
7 72.14.236.13 (72.14.236.13) 53.271 ms 55.641 ms 57.164 ms
8 74.125.224.214 (74.125.224.214) 59.162 ms 62.871 ms 63.266 ms
Con este comando nos podemos dar cuenta de posibles ataques de de suplantación de identidad.
sábado, 11 de junio de 2011
Dar permisos de administrador sólo a ciertos programas ejecutados por ciertos usuarios
En ocasiones, muchos programas necesarios para el trabajo de ciertos usuarios o grupos de usuarios necesitan ser ejecutados como root. Sin embargo debido a la política de seguridad de nuestra organización no podemos darle acceso a todo el sistema. Para solucionar esto, Linux cuenta con un comando llamado SUDOERS. Que una vez configurado nos ayudará a especificar permisos especiales para grupos o usuarios.
Descripción
SUDOERS es una lista en donde se agregan usuarios asociados a ciertos comandos qué sin esta configuración sólo podrían ser ejecutados por el root.
Básicamente se componen por aliases de comandos.
Hay cuatro tipos de alias:
User_Alias, Runas_Alias, Host_Alias y Cmnd_Alias.
User_Alias ::= NAME '=' User_List
Runas_Alias ::= NAME '=' Runas_List
Host_Alias ::= NAME '=' Host_List
Cmnd_Alias ::= NAME '=' Cmnd_List
NAME ::= [A-Z]([a-z][A-Z][0-9]_)*
Donde NAME es el nombre del comando a invocar.
User_List la lista de usuarios permitidos.
Host_List la lista de servidores permitidos.
Cmnd_List la lista de comandos.
Para mayor información revisa el manual de SUDOERS.
http://linux.die.net/man/5/sudoers
Ejemplo.
Tengo un servidor web con DNS dinámico. Para que asocie el ip dinámico que me da mi provedor de internet con un nombre (harpia.no-ip.org) debo estar ejecutando un comando llamado noip2 .
Sin embargo, estoy cansado de tener que ejecutar ese comando como root. Se puede solucionar de muchas formas pero dado todo lo que vimos con SUDOERS lo vamos a hacer así.
Práctica
Lo primero que pensamos es modificar el archivo sudoers ubicado en:
/etc/sudoers (cómo superusuario obviamente!)
ATENCION: el archivo originalmente no se podrá editar porque ni siquiera el dueño (root) tiene permisos de escritura. Si los cambiamos (sudo chmod o+w sudoers) habremos cambiado la configuración de sudoers y no podremos volver a utilizar el comando sudo! Por tanto ni siquiera podremos volver a editar sudoers para regresarlo a su forma original. Si te pasó esto revisa lo siguiente: http://kubuntuforums.net/forums/index.php?topic=3114059.0
También puedes volver a editar el archivo entrando al kernel a prueba de fallos.
Para realizar esto necesitaremos del comando visudo, un editor de texto que sólo modifica al archivo sudoers.
Ejemplo para apagar la computadora sin ser root
# /etc/sudoers
#
# This file MUST be edited with the 'visudo' command as root.
#
# See the man page for details on how to write a sudoers file.
#
Defaults env_reset
# Uncomment to allow members of group sudo to not need a password
# %sudo ALL=NOPASSWD: ALL
# Host alias specification
# User alias specification
User_Alias USERS = juan, juanlternate
# Cmnd alias specification
Cmnd_Alias APAGAR = /sbin/shutdown -h now, /sbin/halt, /sbin/reboot
Cmnd_Alias IP = /usr/local/bin/noip2
# User privilege specification
# Especificaciones de los usuarios
root ALL=(ALL) ALL
USERS ALL=NOPASSWD: APAGAR,/usr/local/bin/noip2
# Members of the admin group may gain root privileges
%admin ALL=(ALL) ALL
Descripción
SUDOERS es una lista en donde se agregan usuarios asociados a ciertos comandos qué sin esta configuración sólo podrían ser ejecutados por el root.
Básicamente se componen por aliases de comandos.
Hay cuatro tipos de alias:
User_Alias, Runas_Alias, Host_Alias y Cmnd_Alias.
User_Alias ::= NAME '=' User_List
Runas_Alias ::= NAME '=' Runas_List
Host_Alias ::= NAME '=' Host_List
Cmnd_Alias ::= NAME '=' Cmnd_List
NAME ::= [A-Z]([a-z][A-Z][0-9]_)*
Donde NAME es el nombre del comando a invocar.
User_List la lista de usuarios permitidos.
Host_List la lista de servidores permitidos.
Cmnd_List la lista de comandos.
Para mayor información revisa el manual de SUDOERS.
http://linux.die.net/man/5/sudoers
Ejemplo.
Tengo un servidor web con DNS dinámico. Para que asocie el ip dinámico que me da mi provedor de internet con un nombre (harpia.no-ip.org) debo estar ejecutando un comando llamado noip2 .
Sin embargo, estoy cansado de tener que ejecutar ese comando como root. Se puede solucionar de muchas formas pero dado todo lo que vimos con SUDOERS lo vamos a hacer así.
Práctica
Lo primero que pensamos es modificar el archivo sudoers ubicado en:
/etc/sudoers (cómo superusuario obviamente!)
ATENCION: el archivo originalmente no se podrá editar porque ni siquiera el dueño (root) tiene permisos de escritura. Si los cambiamos (sudo chmod o+w sudoers) habremos cambiado la configuración de sudoers y no podremos volver a utilizar el comando sudo! Por tanto ni siquiera podremos volver a editar sudoers para regresarlo a su forma original. Si te pasó esto revisa lo siguiente: http://kubuntuforums.net/forums/index.php?topic=3114059.0
También puedes volver a editar el archivo entrando al kernel a prueba de fallos.
Para realizar esto necesitaremos del comando visudo, un editor de texto que sólo modifica al archivo sudoers.
Ejemplo para apagar la computadora sin ser root
# /etc/sudoers
#
# This file MUST be edited with the 'visudo' command as root.
#
# See the man page for details on how to write a sudoers file.
#
Defaults env_reset
# Uncomment to allow members of group sudo to not need a password
# %sudo ALL=NOPASSWD: ALL
# Host alias specification
# User alias specification
User_Alias USERS = juan, juanlternate
# Cmnd alias specification
Cmnd_Alias APAGAR = /sbin/shutdown -h now, /sbin/halt, /sbin/reboot
Cmnd_Alias IP = /usr/local/bin/noip2
# User privilege specification
# Especificaciones de los usuarios
root ALL=(ALL) ALL
USERS ALL=NOPASSWD: APAGAR,/usr/local/bin/noip2
# Members of the admin group may gain root privileges
%admin ALL=(ALL) ALL
Nueva etapa del blog
El curso de administración de servidores se ha terminado, pero el blog sigue. A partir de ahora agregaremos más información referente a configuraciones, instalaciones y noticias relacionadas al mundo del software libre.
martes, 10 de mayo de 2011
Apache public\_html por usuarios
Sacado de:
Si tenemos una instlación de apache default. Deberemos de tener privilegios de superusuario para modificar el archivo userdir.conf ubicado en la carpeta: /etc/apache2/mods-available/
Ahi deberemos agregar la siguiente línea.
UserDir disabled
UserDir enable usuario1 usuario2
Esto permitirá un sitio web sólo para los usuarios 1 y 2 exclusivamente.
Una vez hecho esto procederemos a cargar los módulos. Para esto debemos crear un enlace simbólico entre mods-available y mods-enabled
sudo ln -s ../mods-available/userdir.load .
sudo ln -s ../mods-available/userdir.conf .
Una vez hecho esto reiniciamos el servidor apache con:
sudo /etc/init.d/apache2 restart
Listo!
jueves, 14 de abril de 2011
Logearse como root en una partición externa al sistema operativo.
Hoy vamos a ver como montar un sistema operativo Linux y administrarlo de forma externa con el comando chroot.
Consideremos el siguiente escenario.
Alguien desconfiguró el grub principal de la máquina sobre la que trabajamos.
La solución es simple, utilizar el comando grub-install. Sin embargo dado que no podemos montar la partición, deberemos utilizar un usb (cd) rescue (live-cd) y una vez funcionando el sistema en vivo. Procederemos a montar la partición donde tengamos instalado el sistema que contiene el grub a reconfigurar.
Para esto utilizaremos los siguientes comandos:
#Root
:~/$ sudo mkdir /mnt/c
:~/$ sudo mount /dev/sda5 /mnt/c/
sudo mount --bind /dev/ /mnt/c/dev/
:~/$ sudo mount --bind /sys/ /mnt/c/sys/
:~/$ sudo mount --bind /proc/ /mnt/c/proc
# :~/$ sudo chroot /mnt/c/
# :~/$ sudo chroot /mnt/c/ bash
# :~/$ sudo umount /mnt/c/dev
# :~/$ sudo umount /mnt/c/proc
# :~/$ sudo umount /mnt/c/sys
# :~/$ sudo umount /mnt/c/
# :~/$ sudo grub-install /dev/sda9 -f
# :~/$ sudo reboot
Listo!
Consideremos el siguiente escenario.
Alguien desconfiguró el grub principal de la máquina sobre la que trabajamos.
La solución es simple, utilizar el comando grub-install. Sin embargo dado que no podemos montar la partición, deberemos utilizar un usb (cd) rescue (live-cd) y una vez funcionando el sistema en vivo. Procederemos a montar la partición donde tengamos instalado el sistema que contiene el grub a reconfigurar.
Para esto utilizaremos los siguientes comandos:
#Root
:~/$ sudo mkdir /mnt/c
:~/$ sudo mount /dev/sda5 /mnt/c/
sudo mount --bind /dev/ /mnt/c/dev/
:~/$ sudo mount --bind /sys/ /mnt/c/sys/
:~/$ sudo mount --bind /proc/ /mnt/c/proc
# :~/$ sudo chroot /mnt/c/
# :~/$ sudo chroot /mnt/c/ bash
# :~/$ sudo umount /mnt/c/dev
# :~/$ sudo umount /mnt/c/proc
# :~/$ sudo umount /mnt/c/sys
# :~/$ sudo umount /mnt/c/
# :~/$ sudo grub-install /dev/sda9 -f
# :~/$ sudo reboot
Listo!
martes, 12 de abril de 2011
Compilación del Kernel
Una vez bajado el kernel de kernel.org
debemos modificar el archivo de configuración.
lo que vamos a hcer primero es ir al directorio de las fuentes y dar los siguientes comandos.
make mrproper
cp .config
make oldconfig
make menuconfig
make
make modules
sudo make modules_install
make install
debemos modificar el archivo de configuración.
lo que vamos a hcer primero es ir al directorio de las fuentes y dar los siguientes comandos.
make mrproper
cp
make oldconfig
make menuconfig
make
make modules
sudo make modules_install
make install
jueves, 31 de marzo de 2011
Conectarse a nuestro servidor nts
La dirección IP en LAN para el servidor donde tenemos instalado el servicio es:
10.0.1.43
La carpeta a la que podemos accesar es:
tourette
Debemos instalar los paquetes siguientes:
apt-get install nfs-kernel-server nfs-common portmap
Para conectarnos, sólo hay que montar el sistema de archivos ntfs en nuestro cliente.
mount -t nfs 10.0.1.43:/srv/tourette nfs/
Si se quiere montar automáticamente hay que modificar el archivo /etc/fstab y agregar lo siguiente:
#montar sistema nfs
10.0.1.43:/srv/tourette /media/nfs nfs defaults 1 2
10.0.1.43
La carpeta a la que podemos accesar es:
tourette
Debemos instalar los paquetes siguientes:
apt-get install nfs-kernel-server nfs-common portmap
Para conectarnos, sólo hay que montar el sistema de archivos ntfs en nuestro cliente.
mount -t nfs 10.0.1.43:/srv/tourette nfs/
Si se quiere montar automáticamente hay que modificar el archivo /etc/fstab y agregar lo siguiente:
#montar sistema nfs
10.0.1.43:/srv/tourette /media/nfs nfs defaults 1 2
Como poner un cliente NFS
Estos pasos están descritos aquí.
http://www.debianhelp.co.uk/nfs.htm
El Network File System (Sistema de archivos de red), o NFS, es un protocolo de nivel de aplicación, según el Modelo OSI. Es utilizado para sistemas de archivos distribuido en un entorno de red de computadoras de área local. Posibilita que distintos sistemas conectados a una misma red accedan a ficheros remotos como si se tratara de locales. Originalmente fue desarrollado en 1984 por Sun Microsystems, con el objetivo de que sea independiente de la máquina, el sistema operativo y el protocolo de transporte, esto fue posible gracias a que está implementado sobre los protocolos XDR (presentación) y ONC RPC (sesión) .[1] El protocolo NFS está incluido por defecto en los Sistemas Operativos UNIX y la mayoría de distribuciones Linux.
Instalación, en inglish porqui somos huevones
http://www.debianhelp.co.uk/nfs.htm
El Network File System (Sistema de archivos de red), o NFS, es un protocolo de nivel de aplicación, según el Modelo OSI. Es utilizado para sistemas de archivos distribuido en un entorno de red de computadoras de área local. Posibilita que distintos sistemas conectados a una misma red accedan a ficheros remotos como si se tratara de locales. Originalmente fue desarrollado en 1984 por Sun Microsystems, con el objetivo de que sea independiente de la máquina, el sistema operativo y el protocolo de transporte, esto fue posible gracias a que está implementado sobre los protocolos XDR (presentación) y ONC RPC (sesión) .[1] El protocolo NFS está incluido por defecto en los Sistemas Operativos UNIX y la mayoría de distribuciones Linux.
- NULL: no hace nada, pero sirve para hacer ping al server y medir tiempos.
- CREATE: crea un nuevo archivo.
- LOOKUP: busca un fichero en el directorio actual y si lo encuentra, devuelve un descriptor a ese fichero más información sobre los atributos del fichero.
- READ y WRITE: primitivas básicas para acceder el fichero.
- RENAME: renombra un fichero.
- REMOVE: borra un fichero.
- MKDIR y RMDIR: creación/borrado de subdirectorios.
- READDIR: para leer la lista de directorios.
- GETATTR y SETATTR: devuelve conjuntos de atributos de ficheros.
- LINK: crea un archivo, el cual es un enlace a un archivo en un directorio, especificado.
- SYMLINK y READLINK: para la creación y lectura, respectivamente, de enlaces simbólicos (en un "string") a un archivo en un directorio.
- STATFS: devuelve información del sistema de archivos.
- ROOT, para ir a la raíz (obsoleta en la versión 2).
- WRITECACHE: reservado para un uso futuro.
En la versión 3 del protocolo se eliminan los comandos se STATFS, ROOT y WRITECACHE; y se agregaron los siguientes:[3]
- ACCESS: Para verificar permisos de acceso.
- MKNOD: Crea un dispositivo especial.
- READDIRPLUS: una versión mejorada de READDIR.
- FSSTAT: devuelve información del sistema de archivos en forma dinámica.
- FSINFO: devuelve información del sistema de archivos en forma estática.
- PATHCONF: Recupera información POSIX.
- COMMIT: Enviar datos de caché sobre un servidor un sistema de almacenamiento estable.
Instalación, en inglish porqui somos huevones
Installing NFS in Dedian
Making your computer an NFS server or client is very easy.A Debian NFS client needs
# apt-get install nfs-common portmap
while a Debian NFS server needs
# apt-get install nfs-kernel-server nfs-common portmap
NFS Server Configuration
NFS exports from a server are controlled by the file /etc/exports. Each line begins with the absolute path of a directory to be exported, followed by a space-seperated list of allowed clients.
/etc/exports
/home 195.12.32.2(rw,no_root_squash) www.first.com(ro)
/usr 195.12.32.2/24(ro,insecure)
A client can be specified either by name or IP address. Wildcards (*) are allowed in names, as are netmasks (e.g. /24) following IP addresses, but should usually be avoided for security reasons.
A client specification may be followed by a set of options, in parenthesis. It is important not to leave any space between the last client specification character and the opening parenthesis, since spaces are intrepreted as client seperators.
For each options specified in /etc/exports file can be check export man pages.Click here for manpage.
If you make changes to /etc/exports on a running NFS server, you can make these changes effective by issuing the command:
# exportfs -a
viernes, 18 de marzo de 2011
Mecanismo para monitorear la actividad de "su".
La configuración de las variables que el comando "su" utiliza se encuentra generalmente en el archivo /etc/login.defs el cual contiene, entre otras cosas, las opciónes que el comando interpretará, en las últimas versiones "su" utiliza el archivo syslog para monitorear los intentos de uso, sin embargo no guarda la actividad realizada por dicho comando y para habilitarla es necesario descomentar esta línea:
SULOG_FILE /var/log/sulog
Obviamente se puede establecer otro archivo como destino.
SULOG_FILE /var/log/sulog
Obviamente se puede establecer otro archivo como destino.
Determinar cuotas en Linux
Para activar las cuotas en el sistema ubuntu 10.04.
Supongamos este escenario:
"Mediante un mecanismo de cuotas, establecer límites en cuanto a la cantidad máxima de espacio asignado y la cantidad máxima de archivos a cada usuario. Concretamente quisieramos establecer un máximo de 200MB de espacio y un máximo de 1000 archivos."
Para solucionar esto debemos habilitar el manejo de cuotas en nuestro sistema Linux-
Debemos instalar los programas de gestión de cuotas. Estos son:
quotacheck y quotaon.
Ambos se encuentran el los repositorios de debian/ubuntu. Por lo que se puede instalar con aptitude. El paquete que contiene estos comandos es quota .
$ sudo aptitude install quota
Dos pasos
1.- Configuración del sistema para el uso de cuotas.
2.- Modificar el archivo /etc/fstab
(este paso debe repetirse para cada partición del disco que se quiera gestionar con cuotas.)
Debemos añadir una línea al final de los scripts de configuración. (/etc/rc.local)
Podemos asignar diferentes cuotas para usuarios y grupos.
Supongamos que en el sistema esta un grupo de usuarios de GRASS y queremos asignarle aeste grupo una cuota de disco duro de 500GB. Es bien sabido que los mapas ocupan mucha memoria por lo que hay que restringir un mal uso del disco.
En este ejemplo chafa, el grupo de estos usuarios se puede llamar SIG.
Para cada partición, sobre la que se desee cuota, se necesitarán configurar 3 cosas:
Para cada partición se le debe agregar esta opción en el archivo /etc/fstab
En nuestro sistema quedará de la siguiente forma
Más información de fstab en:
https://help.ubuntu.com/community/Fstab
#definir opción de cuotas para la partición 9
#
#/dev/sda9 / ext4 defaults,usrquota,grpquota 0 1
UUID=cdb835e7-460d-49f7-8dad-7956aeef3799 / ext4 errors=remount-ro,usrquota,grpquota 0 1
Aquí estamos especificando que la partición 9 del dispositivo sda, montado en la raíz del sistema con tipo de archivos ext4 tenga las opciones: usrquota, grpquota
Base de datos de cuotas
Debemos crear un archivo para almacenar la información de cuotas de usuario y grupos. Estos archivos están vacios, por defecto. Se encuentran en el directorio. Debemos crear con el comando touch los siguientes archivos en la raiz de la partición.
$sudo touch quota.user
$sudo touch quota.group
Configuración de los parámetros de cuotas
El comando edquota nos da la posibilidad de crear, modificar o eliminar cuotas de usuarios y grupos.
Primero debemos definir los siguiente.
http://www.faqs.org/docs/Linux-mini/Quota.html
edquota ejecuta un editor de texto para modificar el archivo de cuotas que hemos creado. Por default el editor que ejecuta es el que está definido en la variable de entorno $EDITOR
edquote tiene varios paŕametros. (ver: http://publib.boulder.ibm.com/infocenter/aix/v6r1/index.jsp?topic=/com.ibm.aix.cmds/doc/aixcmds2/edquota.htm)
Supongamos que queremos editar el usuario juan.
PARA PODER HACER ESTO SERÁ
NECESARIO REINICIAR EL EQUIPO o volver a montar la partición.
$ sudo edquota -u juan
En terminal veremos algo así.
Disk quotas for user juan (uid 1002):
Filesystem blocks soft hard inodes soft $
/dev/sda9 24 0 0 7 0 $
los ceros indican que no hay cuiotas para la cuenta de juan.
Observemos que hay cuota para los i-nodos. Aquí podemos poner la cuota para los archivos.
Para cumplir con nuestro cometido bastará con modificar este script para que quede así.
para saber cuánto vale un bloque debemos ejecutar el comando
$sudo tune2fs -l /dev/sda9
Disk quotas for user juan (uid 1002):
Filesystem blocks soft hard inodes soft $
/dev/sda9 24 45 50 1000 950 $
Para copiar a otros usuarios podemos copiar la configuración con la opción -p
$ sudo edquota -p juan grillo
listo, lo podemos hacer pa todos los usuarios con:
Checar los siguientes comandos para la gestión de cuotas
quotacheck
quotaon
repquota
Supongamos este escenario:
"Mediante un mecanismo de cuotas, establecer límites en cuanto a la cantidad máxima de espacio asignado y la cantidad máxima de archivos a cada usuario. Concretamente quisieramos establecer un máximo de 200MB de espacio y un máximo de 1000 archivos."
Para solucionar esto debemos habilitar el manejo de cuotas en nuestro sistema Linux-
Debemos instalar los programas de gestión de cuotas. Estos son:
quotacheck y quotaon.
Ambos se encuentran el los repositorios de debian/ubuntu. Por lo que se puede instalar con aptitude. El paquete que contiene estos comandos es quota .
$ sudo aptitude install quota
Dos pasos
1.- Configuración del sistema para el uso de cuotas.
2.- Modificar el archivo /etc/fstab
(este paso debe repetirse para cada partición del disco que se quiera gestionar con cuotas.)
Debemos añadir una línea al final de los scripts de configuración. (/etc/rc.local)
#!/bin/sh -e
#
# rc.local
#
# This script is executed at the end of each multiuser runlevel.
# Make sure that the script will "exit 0" on success or any other
# value on error.
#
# In order to enable or disable this script just change the execution
# bits.
#
# By default this script does nothing.
#Checar cuotas
if [ -x /usr/quotacheck ]
then
echo "Verificando cuotas, esto puede llevar tiempo, vato!"
#Estos argumentos son por esto:
#-a, --all Check all mounted non-NFS filesystems in /etc/mtab
# -v, --verbose quotacheck reports its operation as it progresses. Normally it operates silently. If the option is specified twice, also the current directory is printed (note that printing can slow down the scan measurably).
# -u, --user Only user quotas listed in /etc/mtab or on the filesystems specified are to be checked. This is the default action.
#-g--group Only group quotas listed in /etc/mtab or on the filesystems specified are to be checked.
/usr/quotacheck -avug
echo "completado"
fi
if [ -x /usr/quotaon ]
then
echo "Activando cuotas, carnal!"
/usr/sbin/quotaon -avug
fi
exit 0
#
# rc.local
#
# This script is executed at the end of each multiuser runlevel.
# Make sure that the script will "exit 0" on success or any other
# value on error.
#
# In order to enable or disable this script just change the execution
# bits.
#
# By default this script does nothing.
#Checar cuotas
if [ -x /usr/quotacheck ]
then
echo "Verificando cuotas, esto puede llevar tiempo, vato!"
#Estos argumentos son por esto:
#-a, --all Check all mounted non-NFS filesystems in /etc/mtab
# -v, --verbose quotacheck reports its operation as it progresses. Normally it operates silently. If the option is specified twice, also the current directory is printed (note that printing can slow down the scan measurably).
# -u, --user Only user quotas listed in /etc/mtab or on the filesystems specified are to be checked. This is the default action.
#-g--group Only group quotas listed in /etc/mtab or on the filesystems specified are to be checked.
/usr/quotacheck -avug
echo "completado"
fi
if [ -x /usr/quotaon ]
then
echo "Activando cuotas, carnal!"
/usr/sbin/quotaon -avug
fi
exit 0
Podemos asignar diferentes cuotas para usuarios y grupos.
Supongamos que en el sistema esta un grupo de usuarios de GRASS y queremos asignarle aeste grupo una cuota de disco duro de 500GB. Es bien sabido que los mapas ocupan mucha memoria por lo que hay que restringir un mal uso del disco.
En este ejemplo chafa, el grupo de estos usuarios se puede llamar SIG.
Para cada partición, sobre la que se desee cuota, se necesitarán configurar 3 cosas:
- En el archivo /etc/fstab deberemos agregar la opción usrquota
- En el archivo /etc/fstab deberemos agregar la opción grpquota
- Debemos crear una base de datos de las copias.
Para cada partición se le debe agregar esta opción en el archivo /etc/fstab
En nuestro sistema quedará de la siguiente forma
Más información de fstab en:
https://help.ubuntu.com/community/Fstab
#definir opción de cuotas para la partición 9
#
#/dev/sda9 / ext4 defaults,usrquota,grpquota 0 1
UUID=cdb835e7-460d-49f7-8dad-7956aeef3799 / ext4 errors=remount-ro,usrquota,grpquota 0 1
Aquí estamos especificando que la partición 9 del dispositivo sda, montado en la raíz del sistema con tipo de archivos ext4 tenga las opciones: usrquota, grpquota
Base de datos de cuotas
Debemos crear un archivo para almacenar la información de cuotas de usuario y grupos. Estos archivos están vacios, por defecto. Se encuentran en el directorio. Debemos crear con el comando touch los siguientes archivos en la raiz de la partición.
$sudo touch quota.user
$sudo touch quota.group
Configuración de los parámetros de cuotas
El comando edquota nos da la posibilidad de crear, modificar o eliminar cuotas de usuarios y grupos.
Primero debemos definir los siguiente.
In addition to edquota, there are 3 terms which you should familiarize yourself with: Soft Limit, Hard Limit, and Grace Period.
5.4 Soft Limit
_Soft limit_ indicates the maximum amount of disk usage a quota user has on a partition. When combined with grace period, it acts as the border line, which a quota user is issued warnings about his impending quota violation when passed.
5.5 Hard Limit
Hard limit works only when grace period is set. It specifies the absolute limit on the disk usage, which a quota user can't go beyond his hard limit.
5.6 Grace Period
Executed with the command "edquota -t", grace period is a time limit before the soft limit is enforced for a file system with quota enabled. Time units of sec(onds), min(utes), hour(s), day(s), week(s), and month(s) can be used. This is what you'll see with the command "edquota -t":
Más info en:http://www.faqs.org/docs/Linux-mini/Quota.html
edquota ejecuta un editor de texto para modificar el archivo de cuotas que hemos creado. Por default el editor que ejecuta es el que está definido en la variable de entorno $EDITOR
edquote tiene varios paŕametros. (ver: http://publib.boulder.ibm.com/infocenter/aix/v6r1/index.jsp?topic=/com.ibm.aix.cmds/doc/aixcmds2/edquota.htm)
Supongamos que queremos editar el usuario juan.
PARA PODER HACER ESTO SERÁ
NECESARIO REINICIAR EL EQUIPO o volver a montar la partición.
$ sudo edquota -u juan
En terminal veremos algo así.
Disk quotas for user juan (uid 1002):
Filesystem blocks soft hard inodes soft $
/dev/sda9 24 0 0 7 0 $
los ceros indican que no hay cuiotas para la cuenta de juan.
Observemos que hay cuota para los i-nodos. Aquí podemos poner la cuota para los archivos.
Para cumplir con nuestro cometido bastará con modificar este script para que quede así.
para saber cuánto vale un bloque debemos ejecutar el comando
$sudo tune2fs -l /dev/sda9
Disk quotas for user juan (uid 1002):
Filesystem blocks soft hard inodes soft $
/dev/sda9 24 45 50 1000 950 $
Para copiar a otros usuarios podemos copiar la configuración con la opción -p
$ sudo edquota -p juan grillo
listo, lo podemos hacer pa todos los usuarios con:
Checar los siguientes comandos para la gestión de cuotas
quotacheck
quotaon
repquota
Restaurar tablas de particiones
Sacado de:
http://martybugs.net/linux/image.cgi
http://martybugs.net/linux/image.cgi
|
jueves, 17 de marzo de 2011
Cómo agregar permisos específicos a usuarios
Sacado de:
https://help.ubuntu.com/community/Sudoers
utilizar visudo para editar
este es el archivo de configuración para apagar la compu sin permisos ni passwords para el usuario alternate
https://help.ubuntu.com/community/Sudoers
utilizar visudo para editar
este es el archivo de configuración para apagar la compu sin permisos ni passwords para el usuario alternate
# /etc/sudoers
#
# This file MUST be edited with the 'visudo' command as root.
#
# See the man page for details on how to write a sudoers file.
#
Defaults env_reset
# Uncomment to allow members of group sudo to not need a password
# %sudo ALL=NOPASSWD: ALL
# Host alias specification
# User alias specification
User_Alias USERS = Alternate
# Cmnd alias specification
Cmnd_Alias APAGAR = /sbin/shutdown -h now, /sbin/halt, /sbin/reboot
# User privilege specification
# Especificaciones de los usuarios
root ALL=(ALL) ALL
USERS ALL= APAGAR
# Members of the admin group may gain root privileges
%admin ALL=(ALL) ALL
Después en la consola para apagar bastará con poner:
logeado como usuario Alternate
$ sudo shutdown -h now
para apagar el sistema.
#
# This file MUST be edited with the 'visudo' command as root.
#
# See the man page for details on how to write a sudoers file.
#
Defaults env_reset
# Uncomment to allow members of group sudo to not need a password
# %sudo ALL=NOPASSWD: ALL
# Host alias specification
# User alias specification
User_Alias USERS = Alternate
# Cmnd alias specification
Cmnd_Alias APAGAR = /sbin/shutdown -h now, /sbin/halt, /sbin/reboot
# User privilege specification
# Especificaciones de los usuarios
root ALL=(ALL) ALL
USERS ALL= APAGAR
# Members of the admin group may gain root privileges
%admin ALL=(ALL) ALL
Después en la consola para apagar bastará con poner:
logeado como usuario Alternate
$ sudo shutdown -h now
para apagar el sistema.
Montar servidor FTP en Ubuntu/Debian
Instalar vsftp version 2.3.4 desde el código fuente
Este el el link del código fuente
Observa como en el campo de nombre de usurio dice: anonymous
Una vez conectados debemos ir a la carpeta users/cevans y de ahí descargar la versión 2.3.4
-rw-r--r-- 1 530 530 37028 Nov 7 2009 ftpgrab-0.1.5.tar.gz
En el shell escribimos:
ftp vsftpd.beasts.org
Connected to vsftpd.beasts.org.
220 sphinx.mythic-beasts.com FTP server ready.
Name (vsftpd.beasts.org:root): anonymous
331 Guest login ok, type your name as password.
Password:
230- Welcome to Mythic Beasts Ltd.
230-
230- This system is for authorised users only. All access is logged.
230 Guest login ok, access restrictions apply.
Remote system type is UNIX.
Using binary mode to transfer files.
Connected to vsftpd.beasts.org.
220 sphinx.mythic-beasts.com FTP server ready.
Name (vsftpd.beasts.org:root): anonymous
331 Guest login ok, type your name as password.
Password:
230- Welcome to Mythic Beasts Ltd.
230-
230- This system is for authorised users only. All access is logged.
230 Guest login ok, access restrictions apply.
Remote system type is UNIX.
Using binary mode to transfer files.
Observa como en el campo de nombre de usurio dice: anonymous
Una vez conectados debemos ir a la carpeta users/cevans y de ahí descargar la versión 2.3.4
cd users/cevans
ftp> ls
200 PORT command successful.
150 Opening ASCII mode data connection for '/bin/ls'.
total 6428
-rw-r--r-- 1 530 530 37024 Oct 21 2009 ftpgrab-0.1.3.tar.gz
-rw-r--r-- 1 530 530 37023 Oct 27 2009 ftpgrab-0.1.4.tar.gz
ftp> get vsftpd-2.3.4.tar.gz
local: vsftpd-2.3.4.tar.gz remote: vsftpd-2.3.4.tar.gz
200 PORT command successful.
150 Opening BINARY mode data connection for 'vsftpd-2.3.4.tar.gz' (187043 bytes).
226 Transfer complete.
187043 bytes received in 1.42 secs (128.2 kB/s)
drwxr-x--x 2 530 530 4096 Dec 16 2004 private
drwxr-xr-x 2 530 530 4096 Nov 8 21:00 stuff
drwxr-xr-x 22 530 530 4096 Feb 15 22:39 untar
-rw-r--r-- 1 530 530 90425 Sep 22 2001 vsftpd-0.9.2.tar.gz
-rw-r--r-- 1 530 530 92976 Nov 16 2001 vsftpd-1.0.1.tar.gz
-rw-r--r-- 1 530 530 113205 Jul 31 2002 vsftpd-1.1.0.tar.gz
-rw-r--r-- 1 530 530 115836 Oct 7 2002 vsftpd-1.1.1.tar.gz
-rw-r--r-- 1 530 530 117792 Oct 16 2002 vsftpd-1.1.2.tar.gz
-rw-r--r-- 1 530 530 120817 Nov 9 2002 vsftpd-1.1.3.tar.gz
-rw-r--r-- 1 530 530 130025 May 29 2003 vsftpd-1.2.0.tar.gz
-rw-r--r-- 1 530 530 136041 Nov 13 2003 vsftpd-1.2.1.tar.gz
-rw-r--r-- 1 530 530 136669 Apr 26 2004 vsftpd-1.2.2.tar.gz
-rw-r--r-- 1 530 530 145467 Jul 1 2004 vsftpd-2.0.0.tar.gz
-rw-r--r-- 1 530 530 189 Jul 1 2004 vsftpd-2.0.0.tar.gz.asc
-rw-r--r-- 1 530 530 146231 Jul 2 2004 vsftpd-2.0.1.tar.gz
-rw-r--r-- 1 530 530 189 Jul 2 2004 vsftpd-2.0.1.tar.gz.asc
-rw-r--r-- 1 530 530 151178 Mar 3 2005 vsftpd-2.0.2.tar.gz
-rw-r--r-- 1 530 530 189 Mar 3 2005 vsftpd-2.0.2.tar.gz.asc
-rw-r--r-- 1 530 530 153266 Mar 19 2005 vsftpd-2.0.3.tar.gz
-rw-r--r-- 1 530 530 189 Mar 19 2005 vsftpd-2.0.3.tar.gz.asc
-rw-r--r-- 1 530 530 151811 Mar 5 2005 vsftpd-2.0.3pre1.tar.gz
-rw-r--r-- 1 530 530 152681 Mar 12 2005 vsftpd-2.0.3pre2.tar.gz
-rw-r--r-- 1 530 530 189 Mar 12 2005 vsftpd-2.0.3pre2.tar.gz.asc
-rw-r--r-- 1 530 530 154857 Jan 9 2006 vsftpd-2.0.4.tar.gz
-rw-r--r-- 1 530 530 189 Jan 9 2006 vsftpd-2.0.4.tar.gz.asc
-rw-r--r-- 1 530 530 155985 Jul 3 2006 vsftpd-2.0.5.tar.gz
-rw-r--r-- 1 530 530 189 Jul 3 2006 vsftpd-2.0.5.tar.gz.asc
-rw-r--r-- 1 530 530 158516 Feb 13 2008 vsftpd-2.0.6.tar.gz
-rw-r--r-- 1 530 530 189 Feb 13 2008 vsftpd-2.0.6.tar.gz.asc
-rw-r--r-- 1 530 530 162801 Jul 30 2008 vsftpd-2.0.7.tar.gz
-rw-r--r-- 1 530 530 189 Jul 30 2008 vsftpd-2.0.7.tar.gz.asc
-rw-r--r-- 1 530 530 178636 Feb 18 2009 vsftpd-2.1.0.tar.gz
-rw-r--r-- 1 530 530 197 Feb 18 2009 vsftpd-2.1.0.tar.gz.asc
-rw-r--r-- 1 530 530 180914 May 28 2009 vsftpd-2.1.1.tar.gz
-rw-r--r-- 1 530 530 197 May 28 2009 vsftpd-2.1.1.tar.gz.asc
-rw-r--r-- 1 530 530 180548 Feb 26 2009 vsftpd-2.1.1pre1.tar.gz
-rw-r--r-- 1 530 530 197 Feb 26 2009 vsftpd-2.1.1pre1.tar.gz.asc
-rw-r--r-- 1 530 530 180958 May 29 2009 vsftpd-2.1.2.tar.gz
-rw-r--r-- 1 530 530 197 May 29 2009 vsftpd-2.1.2.tar.gz.asc
-rw-r--r-- 1 530 530 184700 Aug 13 2009 vsftpd-2.2.0.tar.gz
-rw-r--r-- 1 530 530 197 Aug 13 2009 vsftpd-2.2.0.tar.gz.asc
-rw-r--r-- 1 530 530 182050 Jul 7 2009 vsftpd-2.2.0pre1.tar.gz
-rw-r--r-- 1 530 530 197 Jul 7 2009 vsftpd-2.2.0pre1.tar.gz.asc
-rw-r--r-- 1 530 530 184140 Jul 14 2009 vsftpd-2.2.0pre2.tar.gz
-rw-r--r-- 1 530 530 197 Jul 14 2009 vsftpd-2.2.0pre2.tar.gz.asc
-rw-r--r-- 1 530 530 184329 Jul 16 2009 vsftpd-2.2.0pre3.tar.gz
-rw-r--r-- 1 530 530 197 Jul 16 2009 vsftpd-2.2.0pre3.tar.gz.asc
-rw-r--r-- 1 530 530 184420 Jul 18 2009 vsftpd-2.2.0pre4.tar.gz
-rw-r--r-- 1 530 530 197 Jul 18 2009 vsftpd-2.2.0pre4.tar.gz.asc
-rw-r--r-- 1 530 530 185226 Oct 19 2009 vsftpd-2.2.1.tar.gz
-rw-r--r-- 1 530 530 197 Oct 19 2009 vsftpd-2.2.1.tar.gz.asc
-rw-r--r-- 1 530 530 185562 Nov 17 2009 vsftpd-2.2.2.tar.gz
-rw-r--r-- 1 530 530 197 Nov 17 2009 vsftpd-2.2.2.tar.gz.asc
-rw-r--r-- 1 530 530 185554 Nov 12 2009 vsftpd-2.2.2pre1.tar.gz
-rw-r--r-- 1 530 530 197 Nov 12 2009 vsftpd-2.2.2pre1.tar.gz.asc
-rw-r--r-- 1 530 530 187122 Aug 6 2010 vsftpd-2.3.0.tar.gz
-rw-r--r-- 1 530 530 197 Aug 6 2010 vsftpd-2.3.0.tar.gz.asc
-rw-r--r-- 1 530 530 186503 Mar 18 2010 vsftpd-2.3.0pre1.tar.gz
-rw-r--r-- 1 530 530 197 Mar 18 2010 vsftpd-2.3.0pre1.tar.gz.asc
-rw-r--r-- 1 530 530 186992 Mar 26 2010 vsftpd-2.3.0pre2.tar.gz
-rw-r--r-- 1 530 530 197 Mar 26 2010 vsftpd-2.3.0pre2.tar.gz.asc
-rw-r--r-- 1 530 530 187199 Aug 19 2010 vsftpd-2.3.1.tar.gz
-rw-r--r-- 1 530 530 197 Aug 19 2010 vsftpd-2.3.1.tar.gz.asc
-rw-r--r-- 1 530 530 187229 Aug 20 2010 vsftpd-2.3.2.tar.gz
-rw-r--r-- 1 530 530 197 Aug 20 2010 vsftpd-2.3.2.tar.gz.asc
-rw-r--r-- 1 530 530 187001 Feb 15 07:58 vsftpd-2.3.3.tar.gz
-rw-r--r-- 1 530 530 198 Feb 15 07:58 vsftpd-2.3.3.tar.gz.asc
-rw-r--r-- 1 530 530 187043 Feb 15 22:38 vsftpd-2.3.4.tar.gz
-rw-r--r-- 1 530 530 198 Feb 15 22:38 vsftpd-2.3.4.tar.gz.asc
226 Transfer complete.
ftp> get vsftpd-2.3.4.tar.gz
local: vsftpd-2.3.4.tar.gz remote: vsftpd-2.3.4.tar.gz
200 PORT command successful.
150 Opening BINARY mode data connection for 'vsftpd-2.3.4.tar.gz' (187043 bytes).
226 Transfer complete.
187043 bytes received in 1.42 secs (128.2 kB/s)
Verificar firma del tarball:
Para esto debemos descargar el archivo *.asc
¿Qué es asc http://www.fileinfo.com/extension/asc ?
juan@Jaguar:~/ftp$ gpg vsftpd-2.3.4.tar.gz.asc
gpg: Firmado el mar 15 feb 2011 16:38:11 CST usando clave DSA ID 3C0E751C
gpg: Imposible comprobar la firma: Clave pública no encontrada
Debemos conseguir la llave pública del sitio
Probemos...
juan@Jaguar:~/ftp$ gpg vsftpd-2.3.4.tar.gz.asc
gpg: Firmado el mar 15 feb 2011 16:38:11 CST usando clave DSA ID 3C0E751C
gpg: Imposible comprobar la firma: Clave pública no encontrada
Hay qué conseguirla, quizás en el keyserver del MIT
juan@Jaguar:~/ftp$ gpg --keyserver pgpkeys.mit.edu --recv-key 3C0E751C
gpg: solicitando clave 3C0E751C de hkp servidor pgpkeys.mit.edu
gpg: clave 3C0E751C: clave pública "Chris Evans " importada
gpg: Cantidad total procesada: 1
gpg: importadas: 1
vientos!
juan@Jaguar:~/ftp$ gpg vsftpd-2.3.4.tar.gz.asc
gpg: Firmado el mar 15 feb 2011 16:38:11 CST usando clave DSA ID 3C0E751C
gpg: Firma correcta de «Chris Evans »
gpg: AVISO: ¡Esta clave no está certificada por una firma de confianza!
gpg: No hay indicios de que la firma pertenezca al propietario.
Huellas dactilares de la clave primaria: 8660 FD32 91B1 84CD BC2F 6418 AA62 EC46 3C0E 751C
Conformémonos con esto.
ahora, compilemos el código fuente
descomir el tar
leer el archivo INSTALL
Atención a lo siguiente: (sacado del archivo INSTALL)
edit "builddefs.h" to handle compile-time settings (tcp_wrappers build,
etc).
Compilación:
Just type "make" (and mail me to fix it if it doesn't build ;-).
This should produce you a vsftpd binary. You can test for this, e.g.:
Step 2) Satisfy vsftpd pre-requisites
2a) vsftpd needs the user "nobody" in the default configuration. Add this
user in case it does not already exist. e.g.:
[root@localhost root]# useradd nobody
useradd: user nobody exists
2b) vsftpd needs the (empty) directory /usr/share/empty in the default
configuration. Add this directory in case it does not already exist. e.g.:
[root@localhost root]# mkdir /usr/share/empty/
mkdir: cannot create directory `/usr/share/empty': File exists
2c) For anonymous FTP, you will need the user "ftp" to exist, and have a
valid home directory (which is NOT owned or writable by the user "ftp").
The following commands could be used to set up the user "ftp" if you do not
have one:
[root@localhost root]# mkdir /var/ftp/
[root@localhost root]# useradd -d /var/ftp ftp
(the next two are useful to run even if the user "ftp" already exists).
[root@localhost root]# chown root.root /var/ftp
[root@localhost root]# chmod og-w /var/ftp
Instalación, a pata
cp vsftpd /usr/sbin/vsftpd
cp vsftpd.conf.5 /usr/share/man/man5
cp vsftpd.8 /usr/share/man/man8
"make install" doesn't copy the sample config file. It is recommended you
do this:
cp vsftpd.conf /etc
probemos...
Edit /etc/vsftpd.conf, and add this line at the bottom:
listen=YES
This tells vsftpd it will NOT be running from inetd.
Right, now let's try and run it!
Probemos
Ir a donde se instaló vsftpd i.e. /usr/sbin/
root@Jaguar:/usr/sbin# ftp localhost
Connected to localhost.
220 (vsFTPd 2.3.4)
Name (localhost:root): ftp
331 Please specify the password.
Password:
230 Login successful.
Remote system type is UNIX.
Using binary mode to transfer files.
ftp> ls
200 PORT command successful. Consider using PASV.
150 Here comes the directory listing.
226 Directory send OK.
ftp> ls
200 PORT command successful. Consider using PASV.
150 Here comes the directory listing.
226 Directory send OK.
Instalción con inetd
Hagamos todo el chunche.
Inet: Often called a super-server, inetd listens on designated ports used by internet services such as FTP, POP3, and telnet. When a TCP packet or UDP packet arrives with a particular destination port number, inetd launches the appropriate server program to handle the connection.
gopher:
The Gopher protocol /ˈɡoʊfər/ is aTCP/IP Application layer protocoldesigned for distributing, searching, and retrieving documents over the Internet. Strongly oriented towards a menu-document design, the Gopher protocol was a predecessor of (and later, an alternative to) the World Wide Web.
The Gopher protocol was first described in RFC 1436. IANA has assigned TCPport 70 to the Gopher protocol.
Setup
The file /etc/services is used to map port numbers and protocols to service names, and the file /etc/inetd.conf is used to map service names to server names. For example, if a TCP request comes in on port 23, /etc/services shows
telnet 23/tcp
The corresponding line in the /etc/inetd.conf file (in this case, taken from a machine running AIX version 5.1) is
telnet stream tcp6 nowait root /usr/sbin/telnetd telnetd -a
This tells inetd to launch the program /usr/sbin/telnetd with the command line arguments telnetd -a. inetd automatically hooks the socket to stdin, stdout, and stderr of the server program.
Generally TCP sockets are handled by spawning a separate server to handle each connection concurrently. UDP sockets are generally handled by a single server instance that handles all packets on that port.
i.e. TENEMOS QUE MODIFICAR /etc/services y /etc/inetd.conf
5a) If using standard "inetd", you will need to edit /etc/inetd.conf, and add
a line such as:
ftp stream tcp nowait root /usr/sbin/tcpd /usr/local/sbin/vsftpd
(Make sure to remove or comment out any existing ftp service lines. If you
don't have tcp_wrappers installed, or don't want to use them, take out the
/usr/sbin/tcpd part).
inetd will need to be told to reload its config file:
kill -SIGHUP `pidof inetd`
5b) If using "xinetd", you can follow a provided example, by looking at the
file EXAMPLE/INTERNET_SITE/README. Various other examples show how to leverage
the more powerful xinetd features.
Suscribirse a:
Entradas (Atom)